Sonnet and Attention is All You Need
Introduction
In this article, I will show you why Sonnet is one of the greatest Tensorflow library, and why everyone should use it. To support my remarks, I’ll implement a new model from Google Brain team 1, Transformer, which is trained to translate sentences without any recurrent neural network. This model is state of the art in translation task.
At some point, during the article, I will make some back and forth to explane some detail about the model. Skip them if you want!
As stated before, I will be using Sonnet all the way through the blog. It has been developed internally at DeepMind. In essence, the principal feature of Sonnet is to abstract away the scoping mechanism of Tensorflow. If your neural network needs to share a lot of weights, this feature is essential. While giving you powerful abstraction, all you have to do is to group graph operations as Module. If a module is used in multiple parts of the graph, the variables inside the module are reused (without having to specify reuse_scope=True). With Sonnet, you write less code, but you also make it more modular and reusable. Finally, as a lot of modules are implemented as part of the core library, it is even more easy to write modular code in a Sonnet way. For example snt.Linear is a fully connected layer, snt.LSTM is an RNN Cell, snt.BatchApply is a utility to apply a module to every tensor across one or multiple axes.
When experimenting new models, you usually want to train your model on the training set, once in a while evaluate, compute some metrics, store the model weights, and restore from the last checkpoint. Tensorflow’s learn API is designed to make this job easy, letting you focus on developing your model. With Estimator, you only have to define two functions:
input_fn: A generator that Estimator will use to retrieve data into feed to the modelmodel_fn: A function that creates a graph, returns a loss function during training, predictions during inference.
The structure of the repository
The repository will be structured as followed:
- Estimator is created in
attention/algorithms/transformers. - All the core module are in
attention/modules/cores(Multi-Head Attention, Input Embedding, Add & Norm, Feed Forward). - Decoders and Encoders modules are respectively in
attention/modules/decoders, and inattention/modules/encoders. - The full model is in
attention/models. - All training and data processing are run as micro services in
attention/services.
Implementation of the Transformer
The Encoder
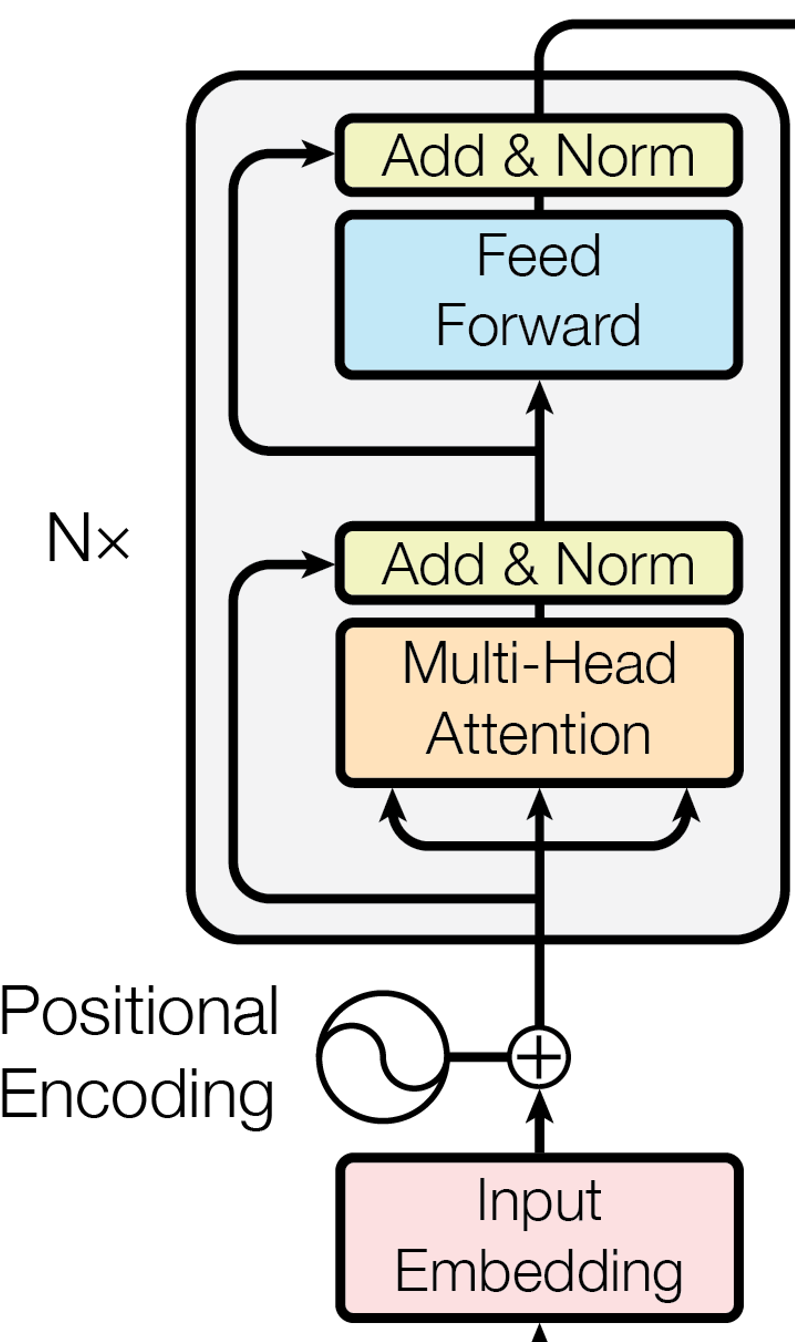 The Encoder is a stack of identical layers (blocks). The Encoder receives as input a batch of padded sequence ids, with their respective length. The encoder output a batch of encoder output, where each sequences identifiers is now a non linearly transformed vector.
The Encoder is a stack of identical layers (blocks). The Encoder receives as input a batch of padded sequence ids, with their respective length. The encoder output a batch of encoder output, where each sequences identifiers is now a non linearly transformed vector.
Here is the code of the Encoder module:
class Encoder(snt.AbstractModule):
def __init__(self, params, block_params, embed_params):
super(Encoder, self).__init__(name="encoder")
self.params = params
self.block_params = block_params
self.embed_params = embed_params
def _build(self, inputs, sequences_length, reuse_embeddings=True):
positionnal_embedding = PositionnalEmbedding(**self.embed_params)
output = positionnal_embedding(inputs)
if self.params.dropout_rate > 0.0:
output = tf.layers.dropout(output, self.params.dropout_rate)
for _ in range(self.params.num_blocks):
encoder_block = EncoderBlock(**self.block_params)
output = encoder_block(output, sequences_length)
return output
This module is one the high-level module that calls the other ones. The structure of this module consists of a constructor and a _build() function. The object must inherit from snt.AbstractModule`. A good practice is to pass in the constructor all parameters that will not vary between two calls of the module. In my case, I’m passing the parameters of the Encoder, of the EncoderBlock, and the Embedding Block. The last two will be passed directly to their own module’s constructor. Also, it is better not to instantiate Tensorflow variables in Sonnet module’s constructor.
The next part is to create the graph of the module, connect inputs, and return outputs, all of that inside the _build() function. You can call your module with the call. The first time, it will call the _build and instantiate the variable in the Graph. Afterwards, if the module is called once more, the module will reuse variables created previously.
For example, in the code above, when EncoderBlock are stacked, I need to re-create a new object each time.
And, here is the code for the EncoderBlock:
The Encoder block module:
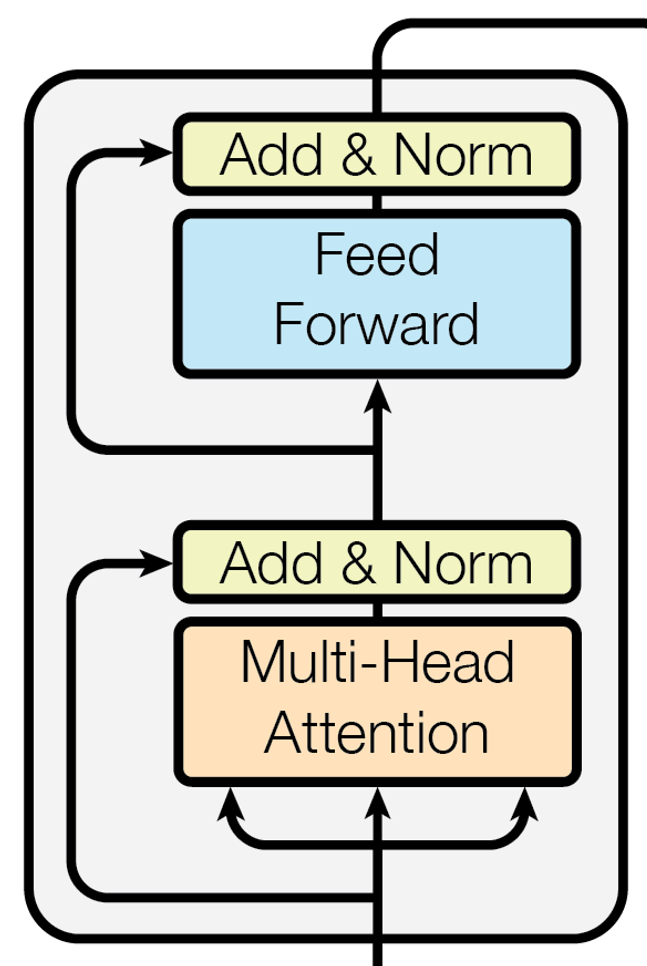
class EncoderBlock(snt.AbstractModule):
def __init__(self, num_heads, hidden_size, dropout_rate):
super(EncoderBlock, self).__init__(name="encoder_block")
self.num_heads = num_heads
self.hidden_size = hidden_size
self.dropout_rate = dropout_rate
def _build(self, inputs, sequence_length):
keys = queries = inputs
keys_len = queries_len = sequence_length
output = MultiHeadAttention(num_heads=self.num_heads, dropout_rate=self.dropout_rate)
(queries=queries, keys=keys,
queries_len=queries_len, keys_len=keys_len)
output = output + queries
output = LayerNorm()(output)
pointwise_module = PointWiseFeedForward(
hidden_size=self.hidden_size,
output_size=output.get_shape().as_list()[-1],
dropout_rate=self.dropout_rate)
output = pointwise_module(output)
output = LayerNorm()(output)
return output
The Embedding Module
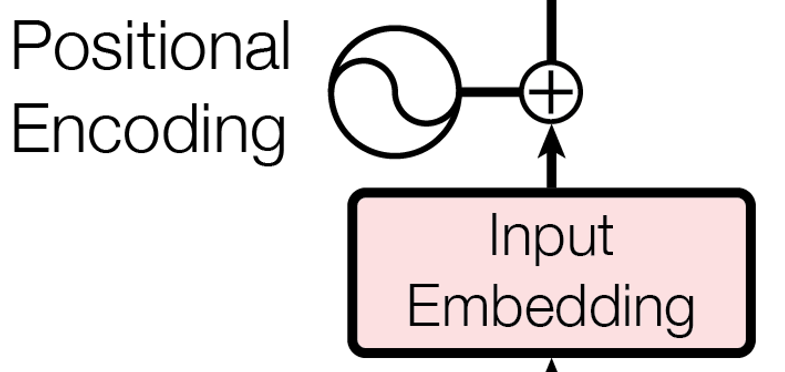
class PositionnalEmbedding(snt.AbstractModule):
def __init__(self, vocab_size, embed_dim):
super(PositionnalEmbedding, self).__init__(name="positional_embedding")
with self._enter_variable_scope():
self.embed = snt.Embed(
vocab_size=vocab_size,
embed_dim=embed_dim,
name="embedding")
def _build(self, ids):
emb_lookup = self.embed(ids)
positionnal_embedding = tf.get_variable('positional_embedding', dtype=tf.float32,
shape=emb_lookup[0].get_shape())
return emb_lookup + positionnal_embedding
As you can see in the code, I created a variable in the constructor which is to avoid when possible. In my case, I don’t want to define the vocabulary size and embedding dimension as an attribute of the module, so I used them only to create the embedding dictionary in the constructor. The Tensorflow variable is created inside the Sonnet module’s scope with enter_variable_scope. This convenient scoping function will not recreate variable defined inside its scope. But if you want to abstract the scoping mechanism of Tensorflow, just define everything in _build()
Thoughts on the paper implementation
The author used fixed positional embedding to encode the position of a token in a sequence. These positional embeddings have the same shape as the token embeddings, and they are computed using cosine and sine of different frequency. In my implementation, I used learned positional embedding as it is simpler to implement and perform equivalently. One drawback is that prediction sequences can’t be larger than sequences encounter during training, as no positional embedding would exist.

The Multi Head Attention Module
The last module example will be the Multi Head Attention Module. If you are not interested in understanding the Transformer, you can skip the next part, otherwise, I’ll recommand you to read the next paragraphs.
A gentle reminder about what attention is
Before seeing any code, let’s review together what attention is. Introduced by Badhanau 2, it is a mechanism allowing to attend over a vector of values. These values are selected by combining a queries vector with a keys vector, each keys referring to a value.
Imagine that you want to cook some chocolate cake, so you’ll need some chocolate, some butter, flour, and eggs. Ingredients will be the values. For all these ingredients, you have your preference; and we all know you love chocolate. Keys will represent how much you enjoy the taste of these ingredients in the cake. Furthermore, each time you cook you always refer to your grandma’s recipe book. So you open it, search for the chocolate cake recipe, and look for each ingredient’s standard proportions (the Queries). Now given each ingredient’s quantity, you want to have each component’s optimal ratio for your final recipe. If you love chocolate, it is likely you’ll add more of it than your grandma’s recipe. Hence, you will attend over your preference, to settle the initial quantities and get the final proportion of each ingredient.
Back to our sheep, attention weights can be calculated as a dot product attention, i.e.,
In the module, there won’t be a single attention, but \(d_k\) ones. All queries, keys and values are vectors; they will be linearly transformed first, before being split into \(d_k\) smaller vectors. On each of these groups, we perform the multi head attention. Then, we collect all the weighted values and concatenate them back into a single vector of the same size as the queries.
In practice, every layer performed multiple attentions.
- In the encoder, as queries, values, and keys are the same, self-attention is made over the output of the previous layer.
- On the decoder side, two form of attention are performed: one between the previous decoder output as queries, and the output of the encoder as keys and values; and one self-attention over the previous layer
When we decode sequences during training, we do self-attention between the decoder input. To prevent the decoder from viewing future information, another mask is applied to the attention
In practise, if \(Queries \cdot Queries^T\) is like that,
keys
t=3 (0.4, 0.3, 0.1, 0.9)
t=2 (0.3, 1.2, 0.3, 0.6)
t=1 (0.1, 0.3, 1.9, 0.2)
t=0 (0.9, 0.6, 0.2, 1.0)
t=0 t=1 t=2 t=3 queries
we mask out some values before applying the Softmax.
keys
t=3 (-inf, -inf, -inf, 0.9)
t=2 (-inf, -inf, 0.3, 0.6)
t=1 (-inf, 0.3, 1.9, 0.2)
t=0 (0.9, 0.6, 0.2, 1.0)
t=0 t=1 t=2 t=3 queries
Note that we also apply a mask when sequences are initially padded.
The implementation
Now that I explained multi attention, let’s see in practice how it looks like:
def _build(self, queries, keys, queries_len, keys_len, values=None):
The module’s inputs are queries, keys, their respective lengths, and potentially values. In our implementation, we don’t need to pass values as they will always be equal to the keys.
We embedded all keys, queries, and values into a same size’s space:
q_w = tf.contrib.layers.fully_connected(queries, input_dim) # batch_size x query_l x d_model
k_w = tf.contrib.layers.fully_connected(keys, input_dim) # batch_size x keys_l x d_model
v_w = tf.contrib.layers.fully_connected(values, input_dim) # batch_size x values_l x d_model
We then split them into num_heads vectors. On each of this queries, keys and values, we apply attention in parallel
# batch_size x num_head x [queries|keys|values]_l x d_model / 8
q_wi = tf.transpose(tf.split(q_w, self.num_heads, axis=2), [1, 0, 2, 3])
k_wi = tf.transpose(tf.split(k_w, self.num_heads, axis=2), [1, 0, 2, 3])
v_wi = tf.transpose(tf.split(v_w, self.num_heads, axis=2), [1, 0, 2, 3])
def dot_product_att(query, key):
head_i = tf.matmul(query, tf.transpose(key, [0, 2, 1])) / key.get_shape().as_list()[-1] ** 0.5
return head_i
We multiply each queries with each keys.
dot_prod_op = snt.BatchApply(dot_product_att)
logits_q_wi_k_wi = dot_prod_op(q_wi, k_wi) # batch_size x num_heads x query_l x key_l
If multi attention is performed on the decoder output with keys equal the previous decoder’s output, we mask out as discussed earlier.
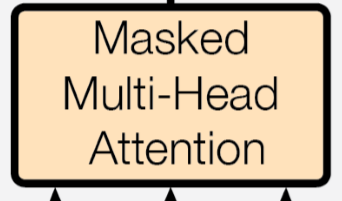
if self.mask_leftward_decoder:
logits_q_wi_k_wi += self.create_mask_for_decoding(*logits_q_wi_k_wi.get_shape().as_list()[2:])
Afterward, we perform softmax
softmax_q_wi_k_wi = tf.nn.softmax(logits_q_wi_k_wi) # batch_size x num_heads x queries_l x keys_l
to get a weighting of our values
attention_qwi_kwi = tf.matmul(softmax_q_wi_k_wi, v_wi) # batch_size x num_heads x queries_l x d_model / 8
At the end, we concatenate again the output values, and project them linearly
# batch_size x queries_l x d_model / 8 x num_heads
attention_qwi_kwi = tf.transpose(attention_qwi_kwi, [0, 2, 3, 1])
# batch_size x queries_l x input_len
concat_attention = tf.reshape(attention_qwi_kwi, [-1, queries.get_shape().as_list()[1], input_dim])
multi_attention = tf.contrib.layers.fully_connected(concat_attention, input_dim)
If you want to see the full code, go there. Note that you can also define utility methods in a Sonnet modules, as long as you ensure not to call this method on their own, but inside the build function. Note that there are many ways to protect methods like the build one is (like @snt.reuse_variables).
Conclusion
In this article, I presented Sonnet. There is way more to know about this excellent library, and I would encourage everyone to have a look at their documentation. If you have some thoughts about the article, or about Sonnet, please write them down in the comment section, I’ll be interested to discuss them. On a side note, I’m also very excited by the promising results of Transformer, and I will be happy to share with you my research on this … module …
Bibliography
-
Attention is all You Need from Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin ↩
-
Neural Machine Translation by Jointly Learning to Align and Translate from Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio will ↩